
Content-aware Spaced Repetition
Spaced repetition systems are powerful, but they have a fundamental blind spot: they don’t understand what your flashcards are about.
To your SRS, a card asking “what’s the capital of Italy?” and another asking “what country is Rome the capital of?” are treated independently, each with its own isolated review history. It has no concept that reviewing related material should reinforce your memory of the whole topic.
At the heart of every SRS is a memory model which predicts how long you’ll remember each card based on your past performance. Most of today’s models ignore the content of the cards entirely. This is where content-aware memory models come in: they account for the semantic meaning of your cards, not just your review ratings.
This is more than a minor tweak for scheduling accuracy. It’s a foundational change that makes it practical to build the fluid, intelligent learning tools many have envisioned: from idea-centric memory systems that test understanding from multiple angles to truly conversational spaced repetition with a voice-enabled AI agent as tutor.
This post explores what content-aware memory models are, and the new kinds of learning experiences they make possible.
Contents
Schedulers and memory models
I find it useful to distinguish between schedulers and memory models. This distinction wasn’t immediately obvious to me when I first approached the topic, but I’ve found it essential for thinking clearly about spaced repetition systems (SRS). Here, I’ll introduce both concepts and I’ll make the case that separating schedulers from memory models enables independent innovation and simplifies the development of each component by isolating user experience (UX) concerns within the scheduler. In the literature, the scheduler is sometimes called the “teacher model” since it decides what to teach, while the memory model is the “student model” since it represents what the student knows.
In Anki and other spaced repetition systems, the scheduler is an algorithm that picks the next card to review today, answering the question “Given the review history of every card in the student’s collection, which cards should the student review in this session?”. In practice, when building a spaced repetition system, this is the question you actually care about. The scheduler’s core job is deciding which cards to show today, not just when each card should ideally be reviewed. A card might be “due” for review, but the scheduler might skip it due to daily review limits, prioritize other overdue cards, or defer it based on other goals.
For a long time, the only scheduler available in Anki was a variant of SuperMemo’s SM-2 scheduler, which dates back to 1987. It’s remarkably simple yet effective. SuperMemo has since advanced its scheduler, now at version SM-18. The latest iterations of the algorithm achieve the same retention levels with fewer reviews, and are more robust when reviews deviate from optimal intervals, for example when a student returns from a break of several weeks. While the SuperMemo schedulers are closed-source, an explanation of how they work is available. FSRS is an open-source scheduler by Jarrett Ye built on similar principles to modern SuperMemo algorithms and can be used in Anki.
A memory model predicts forgetting curves, answering the question “Given the review history of every card in the student’s collection, what are the chances the student remembers a specific card at any given moment?”
We define retrievability as the probability that a student remembers a card at a particular time. In practice, we often model this as a binary outcome where a student either remembers or forgets a card. Some spaced repetition systems allow for more nuanced grading. For example, Anki has four options: “Again”, “Hard”, “Good”, “Easy”. This additional information from the review history can be used to make memory models more accurate.
The forgetting curve plots this retrievability over time. A memory model’s job is to compute these curves based on a student’s review history. Retrievability generally decreases over time, as it becomes more likely that the student will forget the card. For example, here are the forgetting curves estimated by different memory models from the same review history (the figure comes from my master’s thesis):
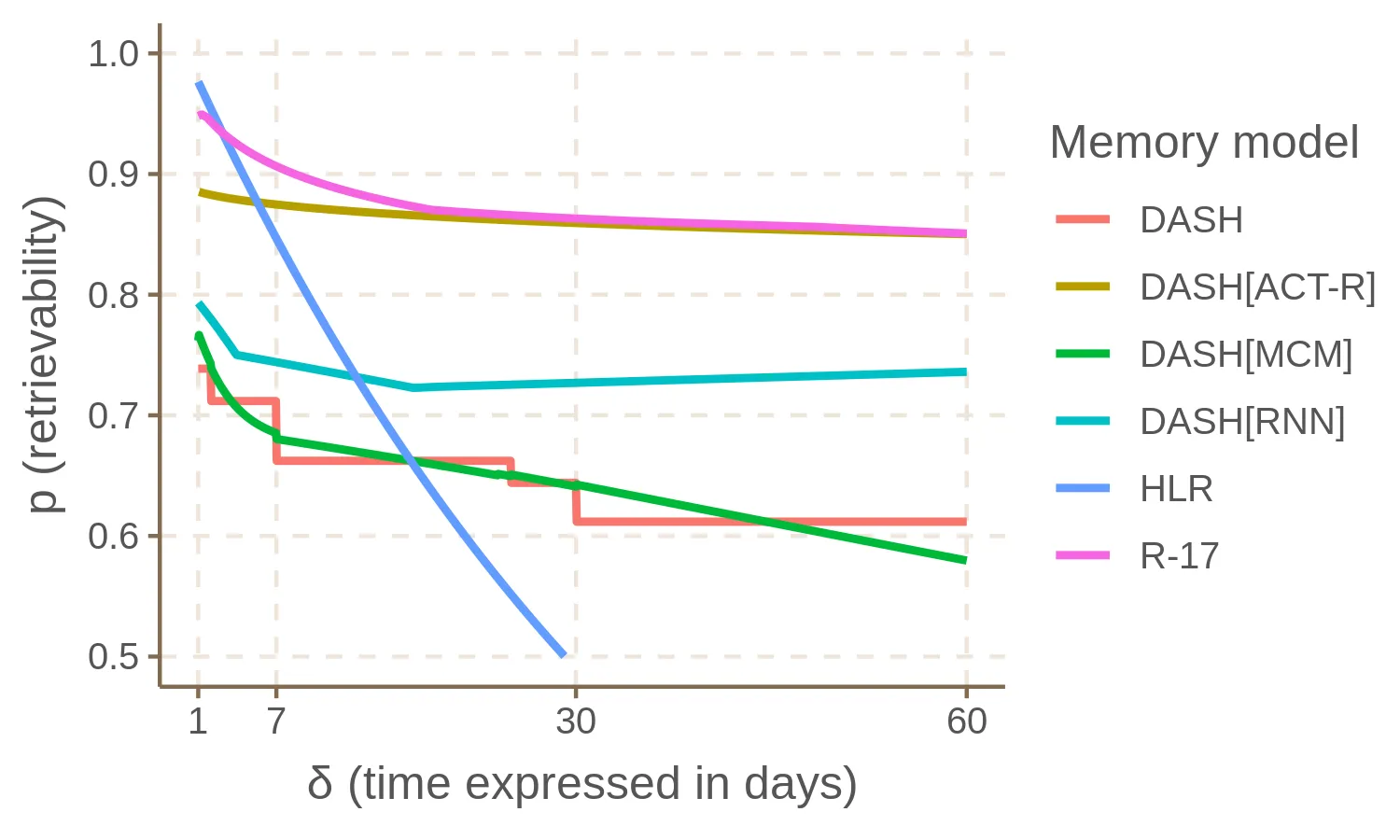
The relationship between schedulers and memory models varies across different systems. A scheduler may or may not use a memory model. For example, the Leitner system and SM-2 do not rely on a memory model to schedule reviews, they are based on simple mechanical rules. Modern schedulers like SM-18 and FSRS instead include a memory model (stability and difficulty are used to compute retrievability). I recommend taking a look at Fernando Borretti’s articles on the implementing SM-2 and FSRS. Note that FSRS ties together the scheduler and the memory model at the implementation level, but they can be separated quite easily to unlock more flexibility in designing the system. There are also schedulers based on model-free reinforcement-learning, that learn a scheduling policy directly from user interactions, without building an explicit, human-interpretable model of forgetting like the ones we’re discussing.
Once you have a memory model that estimates how likely the student is to remember each card, you can build different schedulers with various strategies:
- You can schedule a card for review when retrievability drops below 90%. This is the most common strategy in SRS as far as I can tell. This is more or less what FSRS does, you can also adjust the desired retention to other values.
- You can randomly select cards for review, with probability proportional to how likely they have been forgotten (one minus retrievability). Example.
- You can override the default scheduler behavior for new cards or after a failed review by implementing custom learning and relearning steps. This is also included in most FSRS implementations.
- You can fuzz the intervals (adjust them randomly by small amounts) or apply load balancing to smooth out the amount of reviews scheduled for the student over a few days.
- You can implement different strategies for when the student takes a break of weeks or months. For example, in Rember we mark cards overdue for a week as stale and the student can limit the amount of stale cards in each review session. This is an idea we took from RemNote.
- You can build an exam feature, where the student sets the date for the exam and you schedule reviews in order to achieve high retrievability on that date for cards related to the exam. Example.
- You can account for goals complementary to retention, for example the student workload, the amount of new cards the student is adding, or the estimated answering time for each card. Example.
- You can optimize for long-term outcomes, not just today’s retrievability. For example, if a student fails a card today, reviewing it again tomorrow might boost its future stability more than waiting a week. This forward-looking approach considers how today’s review outcome affects the card’s entire future learning trajectory. Some of the examples above account for similar ramifications. Nate Meyvis has explored similar ideas.
As these examples illustrate, a single, accurate memory model can act as a foundation for a diverse ecosystem of schedulers, each optimized for different goals and user experiences.
The distinction between memory models and schedulers offers two key advantages:
- Independent innovation cycles. We can innovate on schedulers independently of memory models, and vice versa. Scheduler research can treat memory models as a black box to obtain retrievability predictions.
- Separation from UX concerns. We can focus on building better memory models independently of product or UX considerations. The design of schedulers is deeply intertwined with product and UX considerations. For example, a scheduler might ensure a student re-attempts a failed card before the session ends. The primary benefit here might be psychological, providing the student with the assurance of getting it right, rather than a decision optimized purely for long-term retention. Another example is load balancing, the goal of which is primarily improving the student’s experience.
This architectural separation isn’t just theoretical. It enables practical benefits: you can A/B test different scheduling strategies using the same underlying memory model, swap in improved memory models without rebuilding your entire system, and allow users to choose scheduling approaches that fit their learning style while maintaining consistent forgetting predictions underneath.
Most current SRS implementations conflate these concerns. The next generation of systems will likely benefit from treating them as distinct, composable components.
Content-aware memory models
This section explores how leveraging the textual content and semantic relationships between cards can improve memory models.
To the best of my knowledge, most memory models in real-world spaced repetition systems treat each card in isolation. SM-2, SM-18, and FSRS rely solely on each card’s individual review history to predict its forgetting curve. Ignoring the following factors means we are leaving useful information on the table:
- The review histories of related cards. Card semantics allow us to identify related cards. This enables memory models to account for the review histories of all relevant cards when estimating a specific card’s retrievability.
- The card’s textual content. Beyond identifying related cards, the semantic content itself can directly inform the memory model. A model could, for example, estimate the inherent difficulty of a card based on its question or answer text, even before any reviews have taken place.
It’s important to note that “card semantics” encompasses more than simple textual similarity. We’re looking to capture the card’s quality: how effectively the question can activate the memory pathways that lead the student to remember the concept. For example, we need to detect slight ambiguities in the question, which would make it difficult to answer. Moreover, we will likely need to examine the semantics of groups of cards, not just cards in isolation. For example, to memorize a list of three items, you might want a card for each item, plus an integrative card for the entire list. The card for the entire list in isolation would be quite poor in terms of card quality and would be very difficult to remember without the other three cards supporting it.
Informally, this direction proposes shifting the memory model’s focus from:
retrievability(t) = f(t; single_card_history)To leveraging a richer context:
retrievability(t) = f(t; all_cards_history, all_cards_content)Where t is the time since the last review, and each history (whether single_card_history or all_cards_history) is a chronological sequence of review events, typically comprising a timestamp and the student’s rating for that review.
Note that current memory models treat all new cards (cards with no reviews) as the same. Considering the textual content would allow us to obtain more informed initial estimates of a card’s inherent difficulty, leading to better scheduling for cards with no or few reviews compared to uniform defaults.
For example, consider the following collection of cards:
Q: In reinforcement learning, broadly, what is the Bellman equation?
A: An equation that describes the fundamental relationship between the value of a state and the values of its successor states
Q: In reinforcement learning, what equation describes the fundamental relationship between the value of a state and the values of its successor states?
A: The Bellman equation
Q: In reinforcement learning, what's the formula of the Bellman equation?
A: $$ v_{\pi}(s) = \sum_{a} \pi(a|s) \sum_{s', r} p(s', r|s, a) [r + \gamma v_{\pi}(s')] $$All three cards are semantically related, but the first two, being conceptual inversions of each other, share a much stronger connection than with the third, which focuses on the formula. Reviewing either of the first two cards would likely make recalling the other significantly easier. The third card might have a similar effect, but considerably weaker. (Alternatively, if a student successfully reviews either of the first two cards, we should increase our confidence that they’ll recall the other). The third card is also inherently more challenging due to its “less atomic” nature: a student must recall multiple components of the formula, increasing the likelihood of forgetting a single element and marking the card as forgotten.
KARL
This idea has been explored in the literature by Shu et al., 2024 - KARL: Knowledge-Aware Retrieval and Representations aid Retention and Learning in Students, where they introduce the term content-aware scheduling. The memory model in KARL encodes the textual content of the cards with BERT embeddings.
These embeddings play a dual role:
- They facilitate the retrieval of the top-k semantically similar cards from the user’s study history, whose review histories are then passed to the memory model
- The embeddings of the current card and these top-k similar cards are themselves fed into the memory model
The KARL scheduler was evaluated on a dataset consisting of 123,143 study logs on diverse trivia questions, collected from 543 users within a custom flashcard app. It slightly outperformed FSRSv4, which has improved since then, being now at version 6. This result is remarkable because KARL does not model the memory dynamics explicitly, like FSRS does by estimating difficulty and stability, and using a power-law forgetting curve. I wonder how the performance would be for a model that is good at both capturing the memory dynamics, like FSRSv6, and at accounting for card semantics, like KARL.
Small experiments on Rember data
I ran a few small experiments myself that provide additional evidence that this direction is promising. In Rember we group cards around small notes; at the time of the experiment, my account had 4,447 reviews for 940 cards, grouped in 317 notes. You can think of notes as grouping together semantically similar cards.
I ran a couple of experiments on top of FSRS:
exp_1: when the card has no reviews, set the initial stability to the average stability of other cards in the note.exp_2: multiply stability by a constant factor when other cards from the note have been reviewed between now and the card’s last review (the constant factor is optimized using grid search). This simulates a “priming” effect where recent exposure to related concepts reinforces the current card
Stability represents how long the card will last in memory, it’s defined as the interval at which the card’s retrievability drops to 90%.
I compared the following memory models:
random: random retrievability predictions in[0,1]fsrs: FSRSv5 with default parametersfsrs_optimized: FSRSv5 with parameters optimized on the collectionfsrs_exp_1:fsrs+exp_1fsrs_exp_2:fsrs+exp_2fsrs_optimized_exp_1:fsrs_optimized+exp_1fsrs_optimized_exp_2:fsrs_optimized+exp_2
I performed 4-fold cross-validation splitting by note IDs, and compared the models on the same evaluation metrics from my master’s thesis: AUC (measuring discrimination, the highest the better), ICI (measuring the average calibration error, the lower the better), E_max (measuring the maximum calibration error, the lower the better).
The results are summarized in the following table:
| Model | AUC | ICI | E_max |
|---|---|---|---|
random | 0.4887±0.0156 | 0.4235±0.0055 | 0.9193±0.0099 |
fsrs | 0.5708±0.0172 | 0.0364±0.0120 | 0.2720±0.0912 |
fsrs_optimized | 0.6294±0.0115 | 0.0108±0.0041 | 0.1904±0.0689 |
fsrs_exp_1 | 0.5883±0.0248 | 0.0281±0.0086 | 0.2204±0.0640 |
fsrs_exp_2 | 0.5716±0.0159 | 0.0307±0.0079 | 0.2355±0.0867 |
fsrs_optimized_exp_1 | 0.6148±0.0128 | 0.0070±0.0021 | 0.1383±0.0356 |
fsrs_optimized_exp_2 | 0.6386±0.0185 | 0.0075±0.0031 | 0.1285±0.0522 |
The experimental results, though based on a small dataset, indicate a clear trend:
- Incorporating note-level information into FSRS, even with default parameters (
fsrs_exp_1andfsrs_exp_2), generally outperformsfsrsacross all metrics. - The optimal performance is achieved when FSRS is first optimized on the collection and then combined with note-level information.
These results, while preliminary given the dataset size, support the hypothesis that integrating semantic context enhances memory models.
Other considerations
MathAcademy includes an interesting spaced repetition feature, which accounts for the card semantics. They manually create a tree of concepts, with dependencies between them. The spaced repetition scheduler accounts for reviews of prerequisite concepts when scheduling a card. You can read more about how their scheduler works here. Here’s a quote:
Existing spaced repetition algorithms are limited to the context of independent flashcards - but this is not appropriate for a hierarchical body of knowledge like mathematics. For instance, if a student practices adding two-digit numbers, then they are effectively practicing adding one-digit numbers as well! In general, repetitions on advanced topics should “trickle down” the knowledge graph to update the repetition schedules of simpler topics that are implicitly practiced.
This is amazing work, but the scheduler is limited to MathAcademy’s tree of concepts; we need memory models that account for card semantics and apply more generally.
A general caveat might be the computational cost of the scheduler. For example, FSRS can schedule thousands of reviews in a few milliseconds on my M2 MacBook Pro, and therefore it can easily run on-device in a SRS. A memory model that accounts for the review history of all cards and the textual content of the cards will likely be more computationally intensive and might not be able to run on-device without excessive delays or battery drain. KARL addresses this computational challenge by considering only the top-k most semantically similar cards rather than all cards in the collection.
This kind of models will likely be trained on data from many spaced repetition students, which has a few implications:
- Even if a student has no reviews in the system, the model will still be able to estimate the initial difficulty for their cards.
- We are making the implicit assumption that card semantics influence reviews in the same way across students, this might not always be true. For example, a card difficult for one person might be easy for another due to differing familiarity with the topic. However, if a card is hard to remember for most students, it is reasonable to assume it will be hard for others. Potential solutions include: focusing on how the question relates to the underlying topic, rather than the topic itself, or somehow modeling the student’s ability.
UX unlocks
While accuracy improvements are valuable, the bigger impact comes from the UX opportunities unlocked by card semantics. By removing the rigid coupling between cards and their review histories, content-aware memory models give designers of spaced repetition systems much more freedom.
Here’s a concrete example of this constraint in action. When we started working on Rember (in the pre-LLM era), we considered building a fully markdown-based SRS. The main reason we dropped the idea is that you need an ID for each card, to link a card to its review history. Keeping IDs in the markdown quickly gets messy. You end up with something like:
[card:abcxyz]
Q: What's the capital of Italy?
A: RomeWhich is far from ideal, it’s fragile since the user might accidentally edit the ID, or end up with duplicate IDs by copy-pasting cards.
Solutions that get rid of the IDs were all dead-ends. You cannot rely on exact textual matches because the user might edit a card, and you don’t want to reset the review history if the user fixes a typo. You cannot rely on the relative position of the card in the document, as the user might move cards around. Forcing a GUI on top of the markdown that takes care of the IDs is viable, but kinda defeats the point of markdown.
The key insight is decoupling cards from their specific review histories. Instead of linking reviews to card IDs, the memory model considers only a universal history of content-based reviews, as triples: (rating, timestamp, card's textual content). This eliminates the need for card consistency over time. There’s no “card’s review history” anymore, a single “review history” spans the entire student’s collection.
The scheduler can then assess the retrievability of all current cards in a student’s collection, including newly added ones, without relying on past review IDs. Students can edit cards freely without disrupting the scheduler. The memory model, using semantic understanding, differentiates between minor stylistic edits (like typos, which maintain the core meaning) and substantive changes to the card’s content (like replacing an answer, which would alter its semantic meaning sufficiently to be treated as a distinct card).
This decoupling also simplifies systems that dynamically generate prompts. Andy Matuschak explored bringing ideas rather than cards into the system. Prompts are dynamically generated during each review session to test the ideas from multiple angles, and evolve over time as you get more familiar with the ideas (see his Patreon post Fluid practice for fluid understanding or his public notes). Content-aware memory models make this approach much more tractable. Current schedulers assume a review history per card. For dynamically generated prompts, this forces an awkward choice: either treat each unique prompt variation as a new card, losing its connection to the core idea, or group them coarsely at the idea level, which likely leads to under-reviewing the individual prompts. Content-aware memory models, however, naturally handle this gray area.
Taking this further, we could design a SRS where the flashcard-based review session is replaced with a conversation with a voice-enabled AI agent that asks questions or engages in open-ended discussion. This is part of the idea of conversational spaced repetition explored by David Bieber. The AI agent could track the key ideas or concept the student goes over during the conversation, somehow judging whether the user could remember them or not. The content-aware memory model should be able account for those less structured reviews, even if they don’t directly map to Q&A cards.
Additional benefits include:
- Having duplicates cards in the system is less disruptive to the review practice, since the scheduler will consider them as one and the same (even though you might still want to implement ways to detect and remove them from the system).
- Reduced migration costs between SRS. Current importers must meticulously map both cards and review histories. With content-aware memory models, importing reviews could leverage the prior system’s textual card representation, enabling the new model to “understand” review histories from any system, regardless of perfect content mapping.
While this approach reduces some direct user control over individual card histories, such as manually resetting a specific card’s schedule, I believe we can mitigate the problem and that the benefits of the approach far outweigh the costs.
In summary, I predict that content-aware memory models will make it much easier to design and build new interfaces for memory systems. They remove annoying hurdles that occupy the minds of SRS developers.
Data problem
The main challenge in building content-aware memory models is lack of data. To my knowledge, no publicly available dataset exists that contains real-world usage data with both card textual content and review histories.
KARL, mentioned above, is trained on a dataset collected by paying users to review trivia flashcards on a custom app. I would hesitate to rely on a memory model trained solely on artificial data for my own spaced repetition practice. FSRS is trained on anki-revlogs-10k, a large dataset consisting of more than 200M reviews from 10k Anki collections. The dataset includes only card, note, and deck IDs, omitting their textual content due to Anki’s Privacy Policy, which states:
In the interests of research and product development, we may use your review history and options (but not the text or media on cards) for statistical purposes, such as calculating the average pass rate across all users.
While other review datasets exist, a crucial missing piece is a large dataset that:
- Is non-commercial and can be used for research purposes
- Includes review histories
- Includes cards’ textual content
- Covers a wide range of topics (e.g. not just language learning data)
Building on Nate Meyvis’s insights, I’ll add another requirement (I’ll discuss below why this is important):
- A small fraction of the reviews are scheduled at random to provide unbiased data points
Some of the challenges with data coming from spaced repetition systems:
- The data is sparse. Limited to a time-stamped binary sequence of review ratings, spaced repetition data offers only a faint and insufficient signal to fully reconstruct the complex, dynamic state of a student’s memory.
- The data is incomplete. The limited data captured by spaced repetition systems fails to account for crucial out-of-system interactions that significantly shape a student’s memory. Students interact with material outside the SRS: through reading, conversation, or practical application. These interactions, important for memory, are not captured by the system. Furthermore, each review significantly alters the card’s future schedule. Consequently, unrecorded external recall events can have a substantial but uncaptured effect on the memory state assumed by the system.
- The data is biased. Spaced repetition data is inherently biased by the memory model that schedules reviews, creating a “chicken or the egg” problem where the data used to train the model is influenced by the model itself, potentially hindering further optimization (see this paper). This is why scheduling a small fraction of reviews at random in a real-world SRS could significantly improve the accuracy of memory models.
- The data is self-reported. We assume students provide ratings that truly reflect their inner memory state, but they may mark cards as “remembered” when they’ve actually forgotten them, perhaps to avoid the discomfort of perceived failure.
The strong results achieved by current-generation schedulers like FSRS and SM-18 provide compelling evidence that a valuable signal indeed exists and can be separated from noise, despite the challenges described above.
One potential path forward is an open-source, community-contributed dataset where users voluntarily share their Anki and other SRS data, complete with tools to filter out sensitive content and eventually standardized benchmarks for evaluating memory models. If you’re interested in contributing data, have experience building community-driven datasets, or have thoughts on this approach, I’d love to hear from you.
We’re looking for testers for a new workflow for generating flashcards with AI, if you might be interested sign up for the waitlist at rember.com. The best way to get updates on my work is x dot com.